SemEval-2015 Task 3: Answer Selection in Community Question Answering
SUMMARY
- Task: Answer selection in community question answering data (i.e., user generated content)
-
Features:
- The task is related to an application scenario, but it has been decoupled from the IR component to facilitate participation and focus on the relevant aspects for the SemEval community.
- More challenging task than traditional question answering
- Related to textual entailment, semantic similarity, and NL inference
- Multilingual: Arabic and English
- Target: We target semantically oriented solutions using rich language representations to see whether they can improve over simpler bag-of-words and word matching techniques
TASK DESCRIPTION
Community question answering (QA) systems are gaining popularity online. Such systems are seldom moderated, quite open, and thus they have little restrictions, if any, on who can post and who can answer a question. On the positive side, this means that one can freely ask any question and expect some good, honest answers. On the negative side, it takes efforts to go through all possible answers and make sense of them. For example, it is not unusual for a question to have hundreds of answers, which makes it very time consuming to the user to inspect and winnow.
We propose a task that can help automate this process by identifying the posts in the answer thread that answer the question well vs. those that can be potentially useful to the user (e.g., because they can help educate him/her on the subject) vs. those that are just bad or useless.
Moreover, for the special case of YES/NO questions we propose an extreme summarization version of the task, which asks for producing a simple YES/NO summary of all valid answers.
So, in short:
-
Subtask A: Given a question (short title + extended description), and several community answers, classify each of the answers as
- definitely relevant (good),
- potentially useful (potential), or
- bad or irrelevant (bad, dialog, non-English, other)
- Subtask B: Given a YES/NO question (short title + extended description), and a list of community answers, decide whether the global answer to the question should be yes, no or unsure, based on the individual good answers. This subtask is only available for English.
Find below an English example, which is also a YES/NO type of question. Answers 2 and 4 are good, answer 1 is potentially useful and answer 3 is bad. Moreover, based on answers 2 and 4, the answer to the question is most likely NO.
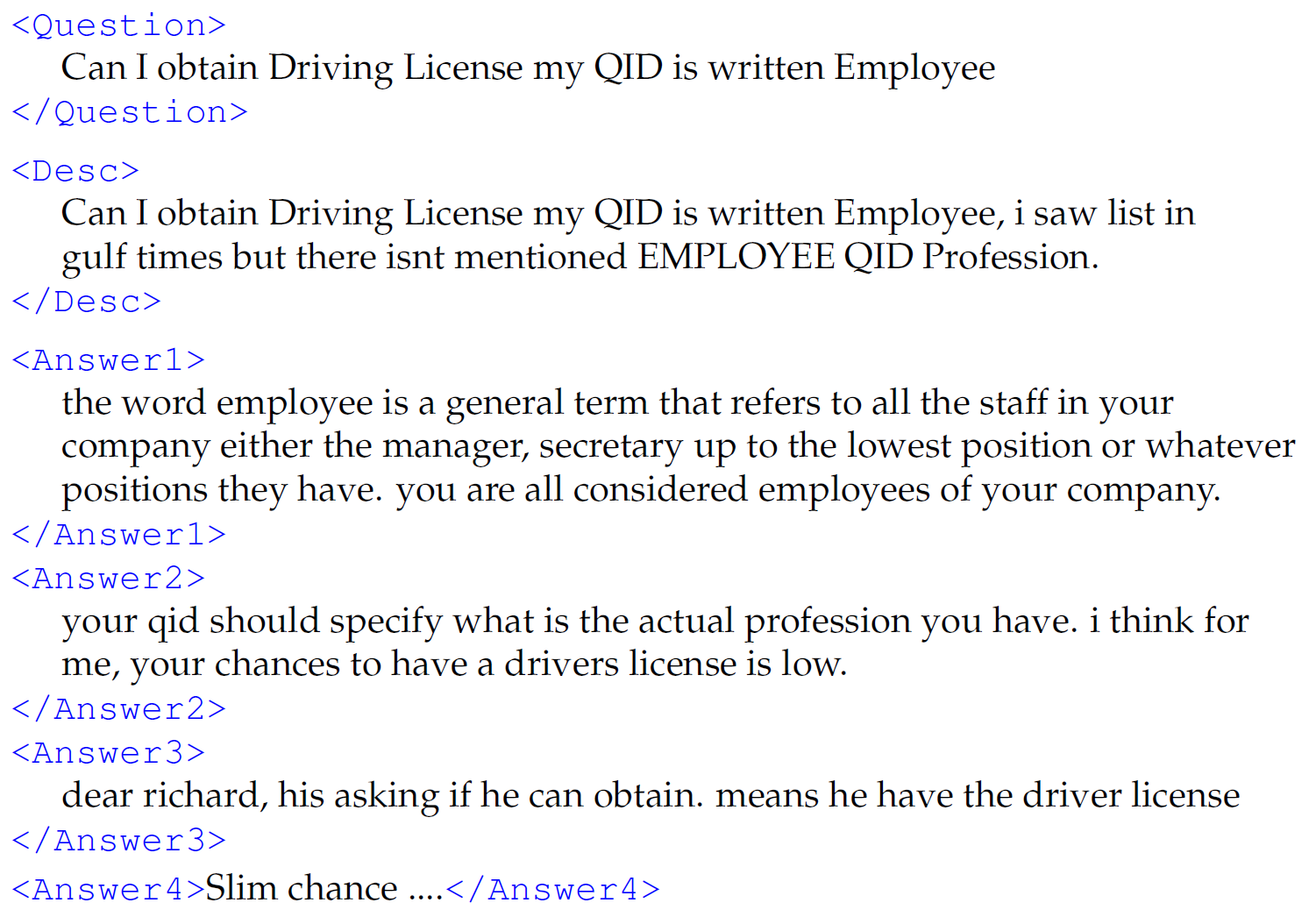
Please, check here for a more detailed description of the English and Arabic datasets. Also, you can freely download the datasets and associated tools that were used by the participants in the task.
Acknowledgements: This research is part of the Interactive sYstems for Answer Search (Iyas) project, conducted by the Arabic Language Technologies (ALT) group at the Qatar Computing Research Institute (QCRI), HBKU within the Qatar Foundation.