Representations
Motivation
As additional background to the task, this page provide a high-level description for each of our three types of semantic dependency graphs, in lexicographic order. For a first impression, please consult our example graphs for a single sentence. For further information, please consult the external documents linked in each section.
DM: MRS-Derived Semantic Dependencies
These semantic dependencies come from the annotation of Sections 00–21 of the WSJ Corpus with gold-standard HPSG analyses provided by the LinGO English Resource Grammar (ERG). Among other layers of linguistic analysis, this resource—dubbed DeepBank by Flickinger et al. (2012)—includes logical-form meaning representations in the framework of Minimal Recursion Semantics (MRS).
DM bi-lexical semantic dependencies, as used in this task, result from a two-stage ‘reduction’ (i.e. simplification) of full MRS analyses. First, Oepen & Lønning (2006) define a conversion from MRS to variable-free Elementary Dependency Structures (EDS); this step is lossy, in that some scope-related information is discarded. Second, while EDS typically contains dependency nodes that correspond to non-lexical units (e.g. construction-specified semantics, as in nominal compounding or the formation of bare noun phrases), it can be further reduced into strictly bi-lexical form through the conversion defined by Ivanova et al. (2012). Although some aspects of construction-specific semantics can be projected onto binary word-to-word dependencies, this step, too, is not information-preserving, i.e. our DM semantic dependency graphs present a true subset of the information encoded in the full, original MRS.
Well-formed DM graphs have a unique top node, but the structural root(s) of the graph need not be the top node. DM graphs are predominantly semi-connected (with about ten percent exceptions), i.e. all nodes are either reachable from the top by at least one undirected path, or they form ‘unconnected’ singletons (have no incoming or outgoing edges); such singleton nodes correspond to semantically vacuous tokens, e.g. complementizers or relative pronouns. There can be re-entrancies in DM graphs, for example in the analysis of control predicates or relative clauses, but there are no cycles. Role labels in DM (ARG1, ..., ARGn) are semantically ‘bleached’, in the formal sense of allowing unambiguous, per-predicate argument labeling but not aiming to provide a globally consistent role labeling, as underlies for example the notions of proto-agents and proto-patients in PropBank. Copestake (2009) provides a contrastive discussion of the two points of view. Some construction semantics, at the DM level, is encoded through additional role labels, e.g. appos, compound, measure, part, or poss, for apposition, compounding, measure phrases, partitives, or possessives, respectively. Unlike in the underlying ERG (and thus MRS), coordinate structures in DM adopt what is often called a Mel'čukian analysis of coordination (Mel'čuk 1988).
PAS: Enju Predicate–Argument Structures
This data set is derived from the HPSG-based annotation of Penn Treebank, which is used for training the wide-coverage HPSG parser Enju. With a wide-coverage grammar and a probabilistic model obtained from this treebank, Enju can effectively analyze syntactic/semantic structures of English sentences and output phrase structures and predicate-argument structures. The Enju parser has successfully been applied to various NLP applications, including information extraction and machine translation.
While DM comes from manually annotated HPSG analyses, the HPSG treebank of Enju is automatically converted from the original bracketing annotations of Penn Treebank, by the method of Miyao, Ninomiya and Tsujii (IJCNLP 2004). The conversion program has been carefully tuned, although the automatic conversion may produce erroneous analyses due to mis-application of conversion rules and/or annotation errors in the original treebank.
The data set provided in this shared task is a simplified version of predicate-argument structures of the Enju HPSG treebank. Semantic dependencies, such as semantic subject and object, are represented as word-to-word dependencies, while other linguistic features and scope information are removed.
For full details, refer to the following documents of the Enju parser.
- Enju Output Speficications introduce the output format of the Enju parser. The document contains information about predicate argument structures, which are the main target of this shared task (See Section 3 "Predicate argument structures" of the document). Dependency labels provided in this shared task are a concatenation of a value of "pred" and an argument label ("arg1", "arg2", etc.).
- Enju XML Format provides examples of the XML format of the Enju parser, which represents predicate argument structures as well as phrase structures. The data set for this shared task is derived from this format by removing phrase structure information.
PDS: Prague Semantic Dependencies
The Prague Czech-English Dependency Treebank 2.0 (PCEDT 2.0) is a manually parsed Czech-English parallel corpus. The English part contains the entire Wall Street Journal section of the Penn Treebank (http://catalog.ldc.upenn.edu/LDC99T42); these texts have been translated and sentence-aligned to Czech. Only those PTB documents which have both POS and structural annotation (total of 2312 documents) have been made part of this release. We use only the English part of the treebank for the present task.
Each language part is enhanced with a comprehensive manual linguistic annotation in the PDT 2.0 style (Prague Dependency Treebank 2.0, http://catalog.ldc.upenn.edu/LDC2006T01). The main features of this annotation style are:
- dependency structure of the content words and coordinating and similar structures (function words are attached as their attribute values)
- semantic labeling of content words and types of coordinating structures
- argument structure, including a “valency” lexicon for both languages
- ellipsis and anaphora resolution
This annotation style is called tectogrammatical annotation and it constitutes the tectogrammatical layer in the corpus. The English manual tectogrammatical annotation was built above an automatic transformation of the original phrase-structure annotation of the Penn Treebank into surface dependency (analytical) representations, using the following additional linguistic information from other sources:
- PropBank (http://catalog.ldc.upenn.edu/LDC2004T14)
- VerbNet (http://verbs.colorado.edu/~mpalmer/projects/verbnet.html)
- NomBank (http://catalog.ldc.upenn.edu/LDC2008T23)
- flat noun phrase structures (by courtesy of David Vadas and James R. Curran)
A subset of the original tectogrammatical annotation is used for the Prague Semantic Dependencies (PSD) in the SDP context:
- The set of graph nodes is equivalent to the set of surface tokens. PCEDT and PDT t-trees contain additional nodes representing elided elements; these nodes are not available in the PSD reduction. On the other hand, functional and punctuation tokens are visible in the SDP data, although they are normally hidden in PCEDT t-trees.
- The attachment of function words to content words in PCEDT and PDT is ignored. Most function nodes remain unconnected in PSD graphs (with one exception, paratactic structures).
- Coreference links are ignored.
- The PSD graphs do not contain grammatemes.
Most dependency labels mark semantic roles of arguments. The labels are called functors in PCEDT and PDT. Their meaning is detailed in documentation (http://ufal.ms.mff.cuni.cz/pcedt2.0/publications/TR_En.pdf), see page 107 and onwards.
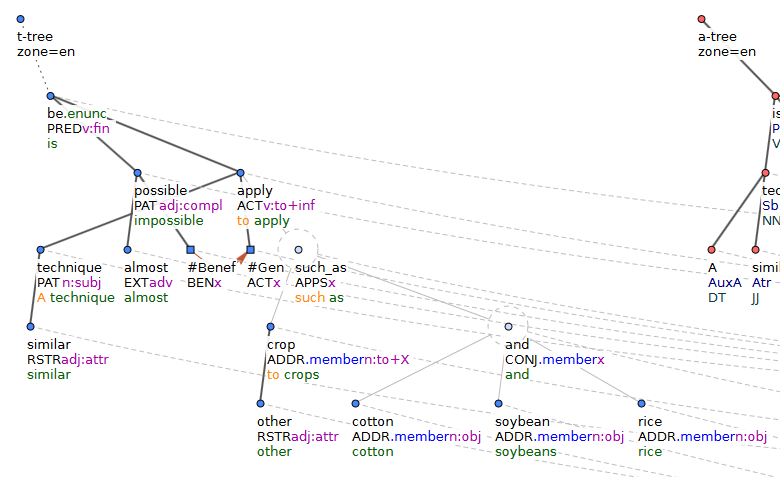
For technical reasons, dependency structures in PCEDT are always rooted trees, even in paratactic constructions where the relations are not true dependencies. In the process of conversion to PSD representation, true dependency relations were extracted. For instance, coordinate actors in PCEDT would be attached to the conjunction, and only the conjunction would be attached to the verb. The former attachments would be labeled ACT (actor) while the latter would be a technical link labeled CONJ. In contrast, the PSD graphs directly show ACT links from the verb to the conjuncts, thus showing the true bi-lexical dependencies. In addition, there are also links from the conjunction to the conjuncts and they are labeled CONJ.member. These links preserve the paratactic structure (which can even be nested) and the type of coordination. The unconnected function words apart, paratactic constructions are the only areas where the SDP graphs are not trees.
Original PCEDT trees always have an artificial root node that does not correspond to any input token. In the extracted PSD graphs, nodes that were direct children of the artificial root in PCEDT are marked as top nodes. Typically there is just one top node per graph. Coordinating conjunctions are not marked as additional top nodes even though they have several outgoing and no incoming edges.
Following is the original PCEDT tectogrammatical tree for our running example: A similar technique is almost impossible to apply to other crops, such as cotton, soybeans and rice.