Task 9: Chinese Semantic Dependency Parsing
The training data has been released!
Please read Data and Tools page.
Overview
This task is a rerun of the task 5 at SemEval 2012 (Che et al., 2012), named Chinese semantic dependency parsing (SDP), investigating "deep" semantic relations within sentences through tree-shape dependencies.
Different from traditional tree-shape syntactic dependency, each head-dependent arc bears a semantic relation, but not a grammatical relation. So semantic dependency parsing results could be used to answer questions directly, like who did what to whom when and where; syntactic dependency parsing results are connected trees defined over all words of a sentence and language-specific grammatical functions, but can’t answer questions in many cases.
However, in the linguistic theory of meaning-text linguistic theory, a theoretical framework for the description of natural languages ( ˇ Zolkovskij and Mel’ˇcuk, 1967), it is said that trees are not sufficient to express the complete meaning of sentences in some cases, which has been proven undoubted in our practice of corpus annotation. This time, not only do we refine the easy-to-understand meaning representation in Chinese in order to decrease ambiguity or fuzzy boundary of semantic relations on the basis of Chinese linguistic knowledge, we extend the dependency structure to directed acyclic graphs that conform to the characteristics of Chinese. Because Chinese is an parataxis language with flexible word orders, and rich latent information is hidden in facial words. Here is a running example:
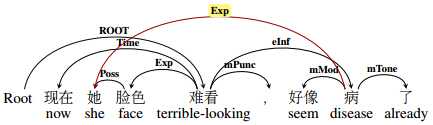
“她(she)” is the argument of “脸色 (face)” and at the same time it is an argument of “病 (disease)”.
Researchers in dependency parsing community realized dependency parsing restricted in a tree structure is still too shallow, so they explored semantic information beyond tree structure in task 8 at SemEval 2014 (Oepen et al., 2014) and task 18 at SemEval 2015. They provided data in similar structure with what we are going to provide, but in distinct semantic representation systems. Once again we propose this task to promote research that will lead to deeper understanding of Chinese sentences, and we believe that freely available and well annotated corpora which can be used as common testbed is necessary to promote research in data-driven statistical dependency parsing.
Data Description
Since texts in rich categories have different linguistic properties with different communication purpose. This task provides two distinguished corpora in appreciable quantity respectively in the domain of NEWS and TEXTBOOKS (from primary school textbooks). Each corpus contains particular linguistic phenomena.
We are going to provide 10,068 sentences of NEWS and 14,793 sentence of TEXTBOOKS. The sentences of news keep the same with the data in task 5 at SemEval 2012, which come from the Chinese PropBank 6.01 (Xue and Palmer, 2003) as the raw corpus to create the Chinese semantic dependency corpus. Sentences were selected by index: 1-121, 1001-1078, 1100-1151. TEXTBOOKS refer to shorter sentences with various ways of expressions, i.e., colloquial sentences (3000), primary school texts (11793). Difference and diversification of resources bring in rich linguistic phenomena. Fan (1998) and Huang and Liao (2003) reduced Chinese sentence patterns into single and compound sentences from the linguistic perspective. Single sentences are categorized into 8 patterns, while compound sentences are categorized into 12 patterns. Each sentence pattern can be found corresponding sentences in our annotated corpus.
Task Description
This task contains two tracks, which are closed track and open track. People participating in closed track could use only the given training data to train their systems and any other additional resource is forbidden. While any knowledge beyond training data is allowed in open track. The closed track encourages participates to focus on building dependency parsing systems on graphs and the open track stimulates researchers to try how to integrate linguistic resource and world knowledge into semantic dependency parsing. The two tracks will be ranked separately. We will provide two training files containing sentences in each domain. There is no rules for the use of these two training data.
Evaluation Methods
During the phase of evaluation, each system should propose parsing results on the previously unseen testing data. Similar with training phase, testing files containing sentences in two domains will be released separately. The final rankings will refer to the average results of the two testing files (taking training data size into consideration). We compare predicted dependencies (predicate-role-argument triples, and some of them contain roots of the whole sentences) with our human-annotated ones, which are regarded as gold dependencies. Our evaluate measures are on two granularity, dependency arc and the complete sentence. Labeled and unlabeled precision and recall with respect to predicted dependencies will be used as evaluation measures. Since non-local dependencies (following Sun et al. (2014), we call these dependency arcs making dependency trees collapsed non-local ones) discovery is extremely difficult, we will evaluate non-local dependencies separately. For sentences level, we will use labeled and unlabeled exact match to measure sentence parsing accuracy. Following Task8 at SemEval 2014, below and in other task-related contexts, we will abbreviate these metrics as (a) labeled precision, recall, F1 and recall for non-local dependencies: LP, LR, LF, NLR; (b) unlabeled precision, recall, F1 and recall for non-local dependencies: UP, UR, UF, NUR; and (c) labeled and unlabeled exact match: LM, UM. When ranking systems participating in this task, we will mainly refer to the average F1 (LF) on the two testing sets.
Reference
- Aleksandr ˇ Zolkovskij and Igor A. Mel’ˇcuk. 1967. O sisteme semantiˇceskogo sinteza. ii: Pravila preobrazovanija [on a system of semantic synthesis (of texts). ii: Paraphrasing rules]. In Nauˇcno-texniˇceskaja informacija 2, Informacionnye processy i sistemy, pages 17–27.
- Nianwen Xue and Martha Palmer. 2003. Annotating the propositions in the Penn Chinese Treebank. Proceedings of the second SIGHAN workshop on Chinese language processing -, 17:47–54.
- Stephan Oepen, Marco Kuhlmann, Yusuke Miyao, Daniel Zeman, Dan Flickinger, Jan Hajiˇc, Angelina Ivanova, and Yi Zhang. 2014. SemEval 2014 The 8th International Workshop on Semantic Evaluation Proceedings of the Workshop Dublin , Ireland. In Proc. of SemEval.
- Wanxiang Che, Meishan Zhang, Yanqiu Shao and Ting Liu. 2012. SemEval-2012 Task 5 : Chinese Semantic Dependency Parsing. In Proceedings of the First Joint Conference on Lexical and Computational Semantics-Volume 1: Proceedings of the main conference and the shared task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation, pages 378–384.
- Weiwei Sun, Yantao Du, Xin Kou, Shuoyang Ding, and Xiaojun Wan. 2014. Grammatical relations in Chinese: Gb-ground extraction and data-driven parsing. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 446–456, Baltimore, Maryland, June. Association for Computational Linguistics.
- Xiao Fan. 1998. The Sentence Types of Chinese. Shanghai Publishing House.