SemEval-2015 Task 12: Aspect Based Sentiment Analysis
Introduction
With the proliferation of user-generated content, interest in mining sentiment and opinions in text has grown rapidly, both in academia and business. The majority of current approaches, however, attempt to detect the overall polarity of a sentence, paragraph, or text span, irrespective of the entities mentioned (e.g., laptops, battery, screen) and their attributes (e.g. price, design, quality). The SemEval-2015 Aspect Based Sentiment Analysis (SE-ABSA15) task is a continuation of SemEval-2014 Task 4 (SE-ABSA14). In aspect-based sentiment analysis (ABSA) the aim is to identify the aspects of entities and the sentiment expressed for each aspect. The ultimate goal is to be able to generate summaries listing all the aspects and their overall polarity such as the example shown in Fig. 1.
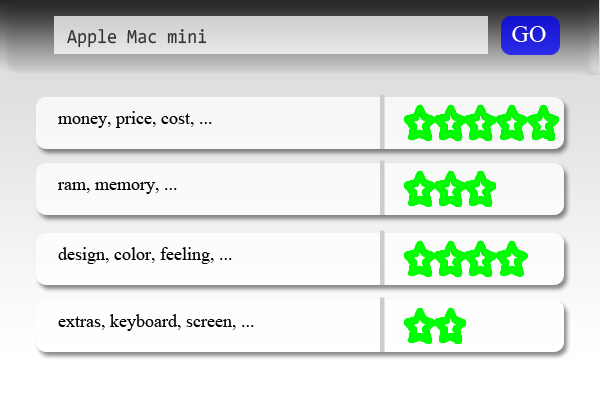
Figure 1: Table summarizing the average sentiment for each aspect of an entity.
Task Description
SE-ABSA15 will focus on the same domains as SE-ABSA14 (restaurants and laptops). However, unlike SE-ABSA14, the input datasets of SE-ABSA15 will contain entire reviews, not isolated (potentially out of context) sentences. SE-ABSA15 consolidates the four subtasks of SE-ABSA14 within a unified framework. In addition, SE-ABSA15 will include an out-of-domain ABSA subtask, involving test data from a domain unknown to the participants, other than the domains that will be considered during training. In particular, SE-ABSA15 consists of the following two subtasks.
Subtask 1: In-domain ABSA
Given a review text about a laptop or a restaurant, identify the following types of information:
Slot 1: Aspect Category (Entity and Attribute). Identify every entity E and attribute A pair E#A towards which an opinion is expressed in the given text. E and A should be chosen from predefined inventories of Entity types (e.g. laptop, keyboard, operating system, restaurant, food, drinks) and Attribute labels (e.g. performance, design, price, quality) per domain. Each E#A pair defines an aspect category of the given text.
The E#A inventories for the laptops domain contains 22 Entity types (LAPTOP, DISPLAY, CPU, MOTHERBOARD, HARD DISC, MEMORY, BATTERY, etc.) and 9 Attribute labels (GENERAL, PRICE, QUALITY, OPERATION_PERFORMANCE, etc.). The entity types and attribute labels are described in the respective annotation guidelines document. Some examples highlighting these annotations are given below:
(1) It fires up in the morning in less than 30 seconds and I have never had any issues with it freezing. → {LAPTOP#OPERATION_PERFORMANCE}
(2) Sometimes you will be moving your finger and the pointer will not even move. → {MOUSE#OPERATION_PERFORMANCE}
(3) The backlit keys are wonderful when you are working in the dark. → {KEYBOARD#DESIGN_FEATURES}
(4) I dislike the quality and the placement of the speakers. {MULTIMEDIA DEVICES#QUALITY}, {MULTIMEDIA DEVICES#DESIGN_FEATURES}
(5) The applications are also very easy to find and maneuver. → {SOFTWARE#USABILITY}
(6) I took it to the shop and they said it would cost too much to repair it. → {SUPPORT#PRICE}
(7) It is extremely portable and easily connects to WIFI at the library and elsewhere. → {LAPTOP#PORTABILITY}, {LAPTOP#CONNECTIVITY}
The E#A inventories for the restaurants domain contains 6 Entity types (RESTAURANT, FOOD, DRINKS, SERVICE, AMBIENCE, LOCATION) and 5 Attribute labels (GENERAL, PRICES, QUALITY, STYLE_OPTIONS, MISCELLANEOUS). The entity types and attribute labels are described in the respective annotation guidelines document. Some examples highlighting these annotations are given below:
(1) Great for a romantic evening, but over-priced. → {AMBIENCE#GENERAL}, {RESTAURANT#PRICES}
(2) The fajitas were delicious, but expensive. → {FOOD#QUALITY}, {FOOD# PRICES}
(3)The exotic food is beautifully presented and is a delight in delicious combinations. → {FOOD#STYLE_OPTIONS}, {FOOD#QUALITY}
(4) The atmosphere isn't the greatest , but I suppose that's how they keep the prices down. → {AMBIENCE#GENERAL}, {RESTAURANT# PRICES}
(5) The staff is incredibly helpful and attentive. → {SERVICE# GENERAL}
Slot 2 (Only for the restaurants domain): Opinion Target Expression (OTE). An opinion target expression (OTE) is an expression used in the given text to refer to the reviewed entity E of a pair E#A. The OTE is defined by its starting and ending offsets in the given text. The OTE slot takes the value “NULL”, when there is no explicit mention of the opinion entity (e.g. pronominal mentions like “they” in example 4 below) or no mention at all (as in example 1 below). For more information and further examples please consult the annotation guidelines document (sec. 4).
(1) Great for a romantic evening, but over-priced. → {AMBIENCE#GENERAL, “NULL”}, {RESTAURANT# PRICES, “NULL”}
(2) The fajitas were delicious, but expensive. → {FOOD#QUALITY, “fajitas”}, {FOOD# PRICES, “fajitas”}
(3) The exotic food is beautifully presented and is a delight in delicious combinations. → {FOOD#STYLE_OPTIONS, “exotic food”}, {FOOD# QUALITY, “exotic food”}
(4) The atmosphere isn't the greatest , but I suppose that's how they keep the prices down. → {AMBIENCE#GENERAL, “atmosphere”}, {RESTAURANT# PRICES, “NULL”}
(5) The staff is incredibly helpful and attentive. → {SERVICE# GENERAL, “staff”}
Slot 3: Sentiment Polarity. Each identified E#A pair of the given text has to be assigned a polarity, from a set P = {positive, negative, neutral}. The neutral label applies to mildly positive or mildly negative sentiment (as in examples 4 and 5 below). Notice that the last two sentences below have not been assigned any aspect categories, OTEs, or sentiment polarities, since they convey only objective information without expressing opinions.
(1) The applications are also very easy to find and maneuver. → {SOFTWARE#USABILITY, positive}
(2) The fajitas were great to taste, but not to see”→ {FOOD#QUALITY, “fajitas”, positive}, {FOOD#STYLE_OPTIONS, “fajitas”, negative }
(3) We were planning to get dessert, but the waitress basically through the bill at us before we had a chance to order. → {SERVICE# GENERAL, “waitress”, negative}
(4) It does run a little warm but that is a negligible concern. → {LAPTOP#QUALITY neutral}
(5) The fajitas are nothing out of the ordinary” → {FOOD#GENERAL, “fajitas”, neutral}
(6) I bought this laptop yesterday. → {}
(7) The fajitas are their first plate → {}
Subtask 2: Out-of-domain ABSA
The participating teams will be asked to test their systems in a previously unseen domain for which no training data will be made available. The gold annotations for Slot 1 will be provided and the teams will be required to return annotations for Slot 3 (sentiment polarity).
Evaluation
The input for the participating systems will be reviews from a particular domain (e.g., laptop or restaurant reviews). Each system will be required to construct all the {E#A, P} tuples for the laptops domain and the {E#A, OTE, P} tuples for the restaurants domain (Fig. 2).
Review id:"1004293"
Judging from previous posts this used to be a good place, but not any longer.
{target:"NULL" category:"RESTAURANT#GENERAL" polarity:"negative" from:"-" to="-"}
We, there were four of us, arrived at noon - the place was empty - and the staff acted
like we were imposing on them and they were very rude.
{target:"staff" category:"SERVICE#GENERAL" polarity:"negative" from:"75" to:"80"}
They never brought us complimentary noodles, ignored repeated requests for sugar,
and threw our dishes on the table.
{target:"NULL" category:"SERVICE#GENERAL" polarity:"negative" from:"-" to:"-"}
The food was lousy - too sweet or too salty and the portions tiny.
{target:"food" category="FOOD#QUALITY" polarity="negative" from:"4" to:"8"}
{target:"portions" category:"FOOD#STYLE_OPTIONS" polarity:"negative" from:"52" to:"60"}
After all that, they complained to me about the small tip.
{target:"NULL" category:"SERVICE#GENERAL" polarity:"negative" from:"-" to:"-"}
Avoid this place!
{target:"place" category:"RESTAURANT#GENERAL" polarity:"negative" from:"11" to:"16"}
Figure 2: ABSA system input/output example.
The output files of the participating systems will be evaluated by comparing them to corresponding files based on human annotations of the test reviews. Participants are free to decide the domain(s), subtask(s), and slot(s) they wish to participate in. The evaluation framework will be similar to that of the SE-ABSA14. Details about the evaluation procedure will be provided shortly.
Similarly to previous SemEval Sentiment Analysis tasks, each team may submit two runs:
Constrained: using ONLY the provided training data (of the corresponding domain).
Unconstrained: using additional resources, such as lexicons or additional training data.
All teams will be asked to report the data and resources they used for each submitted run.
Datasets
Two datasets of ~550 reviews of laptops and restaurants annotated with opinion tuples (as shown in Fig. 2) will be provided for training. Additional datasets will be provided to evaluate the participating systems in Subtask 1 (in-domain ABSA). Information about the domain adaptation dataset of Subtask 2 (out-of-domain ABSA) will be provided in advance.
Organizers
Ion Androutsopoulos (Athens University of Economics and Business, Greece)
Dimitris Galanis (“Athena” Research Center, Greece)
Suresh Manandhar (University of York, UK)
Harris Papageorgiou ("Athena" Research Center, Greece)
John Pavlopoulos (Athens University of Economics and Business, Greece)
Maria Pontiki (“Athena” Research Center, Greece)
References
J. Blitzer, M. Dredze, and F. Pereira. Biographies, Bollywood, Boomboxes and Blenders: Domain Adaptation for Sentiment Classification. ACL, pages 440–447, Prague, Czech Republic, June 2007
G. Ganu, N. Elhadad, and A. Marian, “Beyond the stars: Improving rating predictions using review text content”. Proceedings of the 12th International Workshop on the Web and Databases, Providence, Rhode Island, 2009.
X. Glorot, A. Bordes, and Y. Bengio. Domain Adaptation for LargeScale Sentiment Classification: A Deep Learning Approach. ICML, 2011.
M. Hu and B. Liu, “Mining and summarizing customer reviews”. Proceedings of the 10th KDD, pp. 168–177, Seattle, WA, 2004.
S.M. Kim and E. Hovy, “Extracting opinions, opinion holders, and topics expressed in online news media text”. Proceedings of the Workshop on Sentiment and Subjectivity in Text, pp. 1– 8, Sydney, Australia, 2006.
B. Liu, Sentiment Analysis and Opinion Mining. Synthesis Lectures on Human Language Technologies. Morgan & Claypool, 2012.
B. Liu, Sentiment analysis and subjectivity. In Handbook of Natural Language Processing, Second Edition, N. Indurkhya and F.J. Damerau, Editors. 2010
S. Moghaddam and M. Ester, “Opinion digger: an unsupervised opinion miner from unstructured product reviews”. Proceedings of the 19th CIKM, pp. 1825–1828, Toronto, ON, 2010.
J. Pavlopoulos and I. Androutsopoulos, “Multi-granular aspect aggregation in aspect-based sentiment analysis”. Proceedings of the 14th EACL, Gothenburg, Sweden, pp. 78-87, 2014.
S. Tan, X. Cheng, Y. Wang, and H. Xu. Adapting Naive Bayes to Domain Adaptation for Sentiment Analysis. ECIR, LNCS 5478, pp. 337–349, 2009.
M. Tsytsarau and T. Palpanas. “Survey on mining subjective data on the web”. Data Mining and Knowledge Discovery, 24(3):478–514, 2012.
Z. Zhai, B. Liu, H. Xu, and P. Jia. “Clustering product features for opinion mining”. Proceedings of the 4th International Conference of WSDM, pp. 347–354, Hong Kong, 2011.
M. Pontiki, D. Galanis, J. Pavlopoulos, H. Papageorgiou, I. Androutsopoulos, S. Manandhar. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. Proceedings of the 8th SemEval, 2014.