Overview
Semantic similarity is a core field of Natural Language Processing (NLP) which deals with measuring the extent to which two linguistic items are similar. In particular, the word semantic similarity framework is widely accepted as the most direct in-vitro evaluation of semantic vector space models (e.g., word embeddings) and in general semantic representation techniques. As a result, word similarity datasets play a major role in the advancement of research in lexical semantics. Given the importance of moving beyond the barriers of English language by developing language-independent techniques, the SemEval-2017 Task 2 provides a reliable framework for evaluating both monolingual and multilingual semantic representations, and similarity techniques.
The reference paper for the task (bib) is the following:
- Jose Camacho-Collados, Mohammad Taher Pilehvar, Nigel Collier and Roberto Navigli (2017) SemEval-2017 Task 2: Multilingual and Cross-lingual Semantic Word Similarity. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017). Vancouver, Canada.
SemEval 2017 was co-located with ACL 2017. It was held in Vancouver, Canada, at the Westin Bayshore Hotel on August 3rd/4th, 2017.
Task 2 has two subtasks:
Multilingual subtask |
Cross-lingual subtask |
Five monolingual word similarity datasets:
|
Ten cross-lingual word similarity datasets: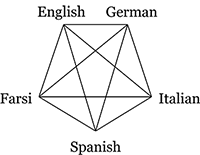 |
What is new?
Task 2 provides large, high-quality and well-balanced datasets composed of nominal pairs that are manually scored according to a well-defined similarity scale. Unlike most existing word similarity datasets, the datasets include:
- Multi-word expressions
- Domain-specific terms
- Named entities
In addition, the multilingual datasets provide an opportunity for the models to be tested on languages other than English, and across different languages.
Target participants
Task 2 provides a reliable benchmark for the development, evaluation and analysis of a wide range of techniques in lexical semantics:
-
Word embeddings
(vector space representations in general)- Monolingual word embeddings: different embedding techniques with their different parameter settings, not only in English but also in four other languages.
- Bilingual and multilingual word embeddings: multilingual models that have a unified semantic space for two or more languages.
-
Semantic similarity techniques
- Similarity measures that use lexical resources (e.g., WordNet, BabelNet).
- Supervised systems that combine multiple measures and features for the computation of semantic similarity.