Data and Tools
CORPORA
TExEval-2 is not restricted to any specific corpora, but participants are encouraged to use Wikipedia documents that are available as XML dumps for English, Dutch, French and Italian. The Wikipedia Extractor python script can be used to clean the text using the following Linux instruction:
bzcat enwiki-latest-pages-articles.xml.bz2 | python WikiExtractor.py -cb 250K -o extracted
TEST DATA
An archive with the complete test data including gold standard taxonomies can be downloaded here.
Test data is released for the following subtasks:
- Taxonomy construction
- Hypernym identification
- Multilingual taxonomy construction
- Multilingual hypernym identification
TExEval-2_testdata_EN_1.0
Download the English test terms here. The trial data package contains the following:
README.txt textual description of this package
environment_eurovoc_en.terms terms from the EuroVoc taxonomy rooted on "environment"
food_en.terms terms from a manual taxonomy rooted on "food"
food_wordnet_en.terms terms from the WordNet taxonomy rooted on "food"
science_en.terms terms from a manual taxonomy rooted on "science"
science_eurovoc_en.terms terms from the EuroVoc taxonomy rooted on "science"
science_wordnet_en.terms terms from the WordNet taxonomy rooted on "science"
TExEval-2_testdata_NL_1.0
Download the Dutch test terms here.
TExEval-2_testdata_FR_1.0
Download the French test terms here.
TExEval-2_testdata_IT_1.0
Download the Italian test terms here.
TRIAL DATA
TExEval_trialdata_1.2
Download the trial data here.
The trial data package contains the following:
README.txt A description
ontolearn_AI.taxo Artificial Intelligence taxonomy [¹]
ontolearn_AI.taxo.eval Human evaluation for the Artificial Intelligence taxonomy relations [¹]
WN_plants.taxo WordNet plants taxonomy
WN_plants.terms WordNet plants terminology
WN_vehicles.taxo WordNet vehicles taxonomy
WN_vehicles.terms WordNet vehicles terminology
Download the trial Dutch terms and taxonomy:
WN_vehicles_dutch.taxo Dutch WordNet vehicles taxonomy
WN_vehicles_dutch.terms Dutch WordNet vehicles terminology
Download the trial French terms and taxonomy:
WN_vehicles_french.taxo French WordNet vehicles taxonomy
WN_vehicles_french.terms French WordNet vehicles terminology
Download the trial Italian terms and taxonomy:
WN_vehicles_italian.taxo Italian WordNet vehicles taxonomy
WN_vehicles_italian.terms Italian WordNet vehicles terminology
** Special characters might not be displayed correctly if you view the files in your browser.
FILE FORMAT
The input file format for taxonomies (.taxo) is tab-separated fields:
relation_id <TAB> term <TAB> hypernym
where:
- relation_id: is a relation identifier;
- term: is a term of the taxonomy;
- hypernym: is a hypernym for the term.
e.g
0<TAB>cat<TAB>animal
1<TAB>dog<TAB>animal
2<TAB>car<TAB>animal
....
The input files format for the system relation evaluation (.taxo.eval) is tab-separated fields:
relation_id <TAB> eval
where:
- relation_id: is a relation identifier;
- eval: is an empty string if the relation is good, an "x" otherwise
e.g.
0<TAB>
1<TAB>
2<TAB>x
....
The input file format for terminologies (.terms) is tab-separated fields:
term_id <TAB> term
where:
- term_id: is a term identifier;
- term: is a domain term.
TExEval_tool_1.0
Download the tool package here.
The tool package contains the following files:
README.txt A description file
TExEval.jar Program for scoring the outputs
runExample.sh Linux script for running the example evaluation
example/gold1.taxo Example gold standard taxonomy
example/sys1.taxo Example of a taxonomy produced by a system
example/sys1.taxo.eval Example file that includes manually evaluated relations from the system taxonomy
example/results.txt Example output of the scoring system
INPUT FORMAT
The input file format for the system and gold standard taxonomies is tab-separated fields:
relation_id <TAB> term <TAB> hypernym
where:
- relation_id: is a relation identifier;
- term: is a term of the taxonomy;
- hypernym: is a hypernym for the term.
e.g
0<TAB>cat<TAB>animal
1<TAB>dog<TAB>animal
2<TAB>car<TAB>animal
....
The input files format for the system relation evaluation is tab-separated fields:
relation_id <TAB> eval
where:
- relation_id: is a relation identifier;
- eval: is an empty string if the relation is good, an "x" otherwise
e.g.
0<TAB>
1<TAB>
2<TAB>x
....
EVALUATION METRICS
The TExEval.jar is a runnable jar, which evaluates a system generated taxonomy against a gold standard taxonomy. The measures reported by the program are:
1) A measure to compare the overall structure of the taxonomy against a gold standard, with an approach used for comparing hierarchical clusters[¹];
2) Precision: the number of correct relations over the number of given relations;
3) Recall: the number of relations in common with the gold standard over the number of gold standard relations;
To run TExEval.jar on your linux machine, open a terminal and enter:
"java -jar TExEval.jar system.taxo goldstandard.taxo root results"
or
"java -jar TExEval.jar system.taxo.eval results"
where:
- system.taxo: is the taxonomy produced by your system;
- system.taxo.eval: is the evaluation of the system produced relations;
- goldstandard.taxo: is the gold standard taxonomy;
- root: is the common root node for the system and the goldstandard taxonomies
- result: is the file where the program will write the results.
By running the runExampleVSGoldStandard.sh, the TExEval.jar compare the following system produced taxonomy:
example/sys1.taxo
0 a entity
1 b a
2 c b
3 d b
4 e b
against the following gold standard taxonomy:
example/gold1.taxo
0 a entity
1 b a
2 c b
3 d b
4 e b
5 f e
6 g e
7 h e
producing the following result.txt file
example/results.txt
Taxonomy file ./example/sys1.taxo
Gold Standard file ./example/gold1.taxo
Root entity
level B Weight BxWeight
0 0.18257418583505536 1.0 0.18257418583505536
1 0.18257418583505536 0.5 0.09128709291752768
2 0.18257418583505536 0.3333333333333333 0.06085806194501845
3 0.0 0.25 0.0
Cumulative Measure 0.16066528353484874
Recall from relation overlap 0.625
where:
1) the two first lines report the arguments passed to the jar application
2) a structural comparison of the system taxonomy against the gold standard taxonomy[¹]
3) the estimated Recall
By running the runExamplePrecision.sh, the TExEval.jar compute the Precision from the following Evaluation file for the system produced relation:
example/sys1.taxo.eval
0
1
2
3
4 x
and produce the following result.txt file:
Taxonomy relation evaluation file ./example/sys1.taxo.eval
Precision from relation evaluation 0.8
TAXONOMY VISUALISATION
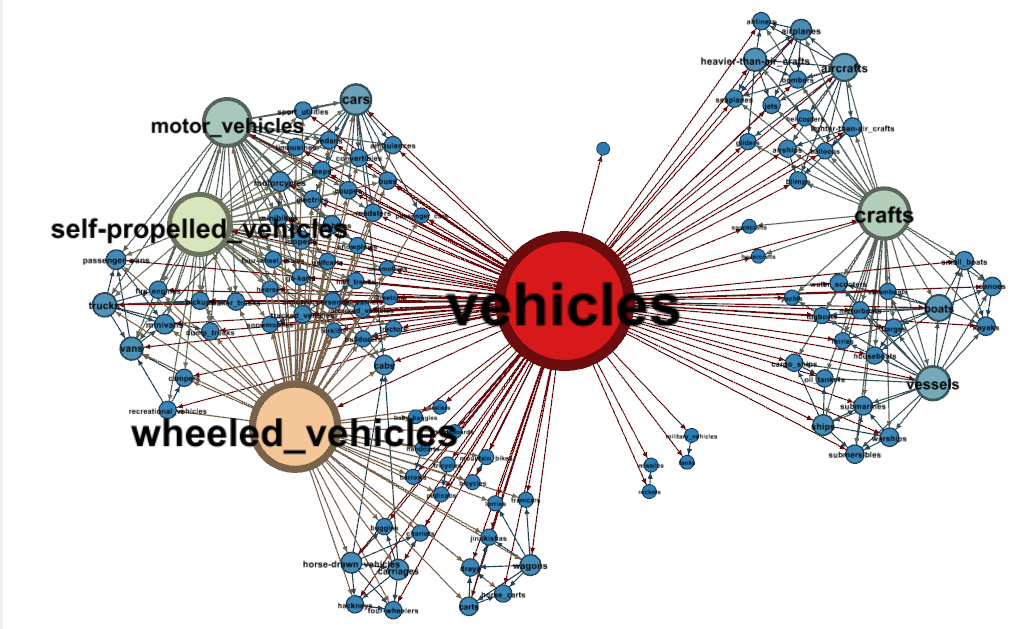
To visualise a taxonomy as a graph we recommend to convert the taxonomy file to the .dot format and to use the Gephi visualization and exploration platform. This tutorial should give you the basics. For example try using the Force Atlas 2 algorithm to layout the graph and node degree for node size and colour. Check the "Prevent Overlap" option and display node labels using the "Node size" option for label size. Check this paper [²] for more information about visualising taxonomies. Below you can find the result for the vehicles taxonomy provided as trial data.
[¹] Paola Velardi, Stefano Faralli, Roberto Navigli. OntoLearn Reloaded: A Graph-based Algorithm for Taxonomy Induction. Computational Linguistics, 39(3), MIT Press, 2013, pp. 665-707.
[²] Hooper, Clare J., Georgeta Bordea, and Paul Buitelaar. "Web science and the two (hundred) cultures: representation of disciplines publishing in web science." In Proceedings of the 5th Annual ACM Web Science Conference, pp. 162-171. ACM, 2013.